

Data is a crucial resource in artificial intelligence (AI). The rapid advancement of AI has significantly increased the value of data, making it one of the most important assets. In the context of AI, data is essential because it is used to train and validate AI models that generate insights, predict outcomes, and make decisions. The quality and quantity of training data can substantially affect the accuracy of these models. Conversely, low-quality or insufficient training data can lead to undesirable outputs and hinder the ability of AI models to generalize accurately when tested with new data.
AI models utilize various types of data, depending on their designated tasks. The most common types include text, images, audio, and video. Each data type has its own characteristics, sources, and formats. Extensive collections of information, such as texts, images, audio, and videos, are referred to as datasets. Typically, these datasets are used to train AI models and are often sourced from the real world, with the web being considered the primary source of data.
The increased adoption of large language models (LLMs) has recently led to a significant rise in demand for both large-scale and high-quality data. Unfortunately, the supply of such data is diminishing, and we are struggling to meet this growing demand. According to the Artificial Intelligence Index Report 2024 presented by Stanford University, researchers from Epoch AI estimate that the current amount of high-quality language data could be depleted within the next two decades. Similarly, image data is anticipated to be fully utilized between the late 2030s and mid-2040s.
This expected shortage of real data could impact the development of AI applications. Additionally, collecting and annotating real-world data for model training can be both expensive and labor-intensive. Privacy concerns, particularly in sensitive fields like healthcare and security, can further complicate data collection efforts. These challenges highlight the need for alternative data sources, such as synthetic data. Gartner, the research firm, predicts that by 2026, 75% of businesses will use generative AI to create synthetic customer data.
Synthetic data is artificial data generated by an AI algorithm trained on real datasets. It can be classified into three types: fully synthetic, partially synthetic, and hybrid. Various techniques can be employed to produce synthetic data, including statistical methods, generative adversarial networks (GANs), and transformer models. Figure 1 illustrates the process of generating and evaluating synthetic data.
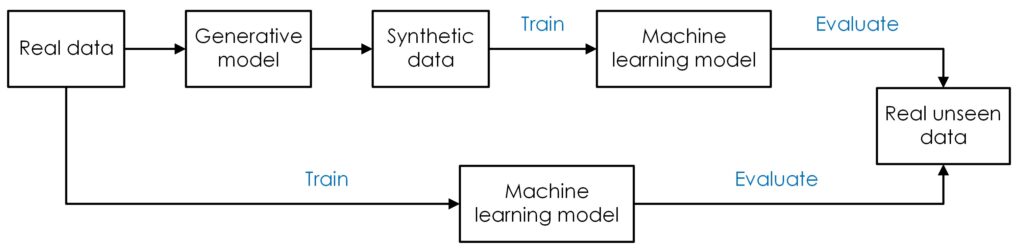
In situations where real data is difficult to obtain or too sensitive to use, synthetic data has shown great potential in enhancing the performance of AI models. This is particularly evident in areas such as medical records and personal financial data. The use of synthetic data has been rapidly adopted across various applications, especially in healthcare, finance, and autonomous driving.
For example, synthetic data plays a significant role in biomedical imaging in healthcare. According to an article published in Stanford Medicine, researchers developed the RoentGen model, a text-to-image generative model that creates realistic X-ray images based on medically relevant text prompts.
In another instance, the AI research team at J.P. Morgan encountered challenges when training AI models for fraud detection. The issue stemmed from the fact that fraudulent cases were far fewer than non-fraudulent cases. To address this, the researchers turned to synthetic data generation to create additional examples of fraudulent cases, ultimately improving the model’s training and performance.
Synthetic data is increasingly being used to enhance the development of autonomous driving technologies. According to a report by Deloitte, synthetic data in driving simulators can create various virtual environments that feature dynamic elements such as vehicles, pedestrians, and weather conditions. These elements closely replicate real-world driving scenarios, ranging from busy urban areas to rural settings.
While synthetic data demonstrates significant potential as an alternative data source, it’s crucial to understand its limitations when training AI models. One notable issue is model collapse, which occurs when an AI model is repeatedly trained on AI-generated data, leading to a decline in performance. Additionally, synthetic data may inherit and reflect biases present in the real-world data from which it was derived.
In summary, although synthetic data has proven its ability to enhance the performance of AI models—especially in situations where real-world data is scarce, sensitive, or expensive to obtain—its limitations pose challenges for widespread adoption. Issues like model collapse and biases must be carefully addressed before AI models can effectively and safely utilize synthetic data.